[toc]
需求
通过excel表中搜集的数据批量导出各种类型的word文档,诸如立案申请书、证据清单等等。
- 数据源:Excel保存名字、性别、出身年月等
- 模板包含:立案申请书模板.docx、证据清单模板.docx等。
本方法主要参考 使用python将Excel数据填充Word模板并生成Word 来实现,并在原脚本的基础上,解决了一些问题,并做了一些优化, 包括但不限于如下:
- 修复macos下的依赖问题
- 一键执行
- 带空格的目录的兼容
- 日志打印优化
- ……
新解决的问题
如下问题不一定每个人都会遇到,本人环境是 Macbook Pro M1 和 macOS Monterey 12.2.1
mac下python3的安装
mac下使用终端执行 python3 自动跳出xcode安装,直接安装即可
因python2存在一些中文编码的问题,故建议使用python3
MailMerge ImportError
1
|
ImportError: cannot import name 'MailMerge' from 'mailmerge'
|
需要安装的包是 docx-mailmerge 而不是 mailmerge
1
2
|
pip3 uninstall mailmerge
pip3 install docx-mailmerge
|
然后就可以正常import
1
|
from mailmerge import MailMerge
|
具体详见 ImportError: cannot import name ‘MailMerge’ from ‘mailmerge’
xlrd.biffh.XLRDError
提示 不支持xlsx文件
1
|
xlrd.biffh.XLRDError: Excel xlsx file; not supported
|
The previous version, xlrd 1.2.0, may appear to work, but it could also expose you to potential security vulnerabilities. With that warning out of the way, if you still want to give it a go, type the following command:
xlrd版本过高,限定在1.2.0版本即可。
1
|
pip3 install xlrd==1.2.0
|
具体详见 xlrd.biffh.XLRDError: Excel xlsx file; not supported [duplicate]
icloud共享目录(目录带空格)
因本人的需求,需要通过iCloud共享对应的文件,但iCloud中的文件包含空格,例如
1
|
/Users/[username]/Library/Mobile\ Documents/com~apple~CloudDocs/[document]
|
增加日期格式转换
直接对xlrd的xldate_as_tuple方法生成的tuple做处理,提取对应的年月日,不依赖datetime、timestamp之类的包,简单高效。
1
2
3
4
|
def excel_date_convert(excel_date):
temp_tuple = xlrd.xldate_as_tuple(excel_date, 0)
format_date='{0}年{1}月{2}日'.format(temp_tuple[0], temp_tuple[1], temp_tuple[2])
return format_date
|
基本文件
批量生成主文件 excel2word.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
|
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import os
import xlrd
import sys
from mailmerge import MailMerge
template_names=['民事起诉书','退费申请书', '证据清单'] # 其他模板文件,加到这个list里即可
template_type='.docx'
def batch(maindir):
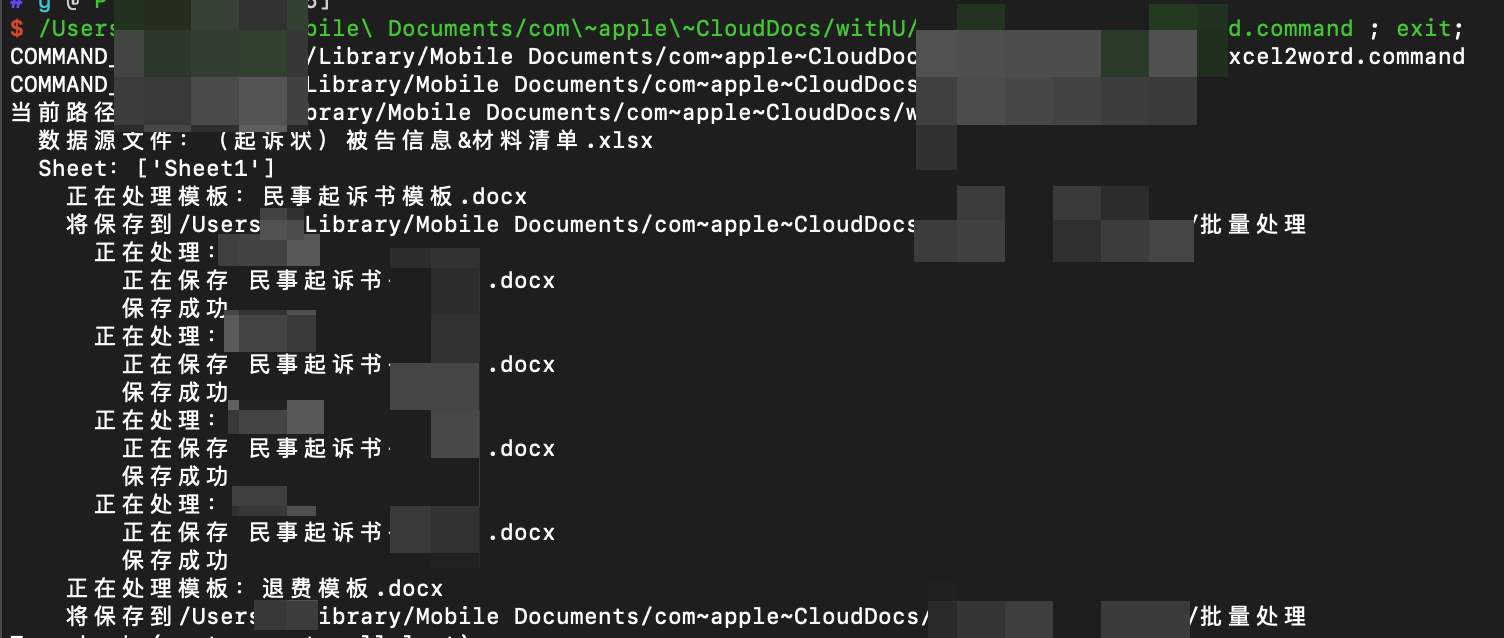
print('当前路径:' + maindir)
for f in os.listdir(maindir+'/.'):
if not os.path.splitext(f)[1] == '.xlsx' and not os.path.splitext(f)[1] == '.xls':
continue
print(' 数据源文件:' + f)
# 打开Excel文件
xl = xlrd.open_workbook(os.path.join(maindir, f))
print(' Sheet:' + str(xl.sheet_names()))
# 读取第一个表
table = xl.sheet_by_name(xl.sheet_names()[0])
# 获取表中行数
nrows = table.nrows
for template_name in template_names:
print(' 正在处理模板:' + template_name + '模板' + template_type)
path_name = os.path.join(maindir, '批量处理')
if not os.path.exists(path_name):
os.makedirs(path_name)
print(' 将保存到' + path_name)
for i in range(1, nrows): # 循环逐行打印
# 第一行为表头,不作为填充数据
doc = MailMerge(maindir + '/' + template_name + '模板' + template_type) # 打开模板文件
# 以下为填充模板中对应的域,
print(' 正在处理:' + str(table.row_values(i)[0]))
doc.merge(
name=str(table.row_values(i)[0]),
gender=str(table.row_values(i)[1]),
birthday=excel_date_convert(table.row_values(i)[2]),
id_card=str(table.row_values(i)[3]),
register_address=str(table.row_values(i)[4]),
phone_number=str(table.row_values(i)[5]),
home_address=str(table.row_values(i)[6]),
loan_balance=str(table.row_values(i)[7]),
due_plus_date=str(excel_date_convert(table.row_values(i)[8])),
)
os.chdir(path_name)
word_name = template_name + '-' + str(table.row_values(i)[0]) + template_type
print(" 正在保存 " + word_name)
doc.write(word_name)
print(" 保存成功")
if doc is None:
doc.close()
def excel_date_convert(excel_date):
temp_tuple = xlrd.xldate_as_tuple(excel_date, 0)
format_date='{0}年{1}月{2}日'.format(temp_tuple[0], temp_tuple[1], temp_tuple[2])
return format_date
if __name__ == '__main__':
batch(sys.argv[1])
|
一键处理 excel2word.command
创建 excel2word.command,内容如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
#COMMAND_DIR=$(cd "$(dirname "$0")";pwd)
#echo $COMMAND_DIR
# 方法一:目录有中文时会乱码,脚本会失败
COMMAND_PATH=$0
echo "COMMAND_PATH" $COMMAND_PATH
COMMAND_DIR=${COMMAND_PATH:0:${#COMMAND_PATH}-18}
# 获取文件所处的绝对路径
# 18这个值是 excel2word.command的长度,因为遇到有中文乱码的问题,使用这个方法来保证可以正常获取到对应的(带空格及带中文)文件路径,未来可以优化
echo "COMMAND_DIR" $COMMAND_DIR
# 方法二:兼容中文
cd "$COMMAND_DIR"
python3 excel2word.py "${COMMAND_DIR}"
|
具体参考
执行
基本文件
下述4种文件需要放置在同一个目录下
- Excel数据表,注意每个数据要按顺序执行,与
table.row_values(i)[【列数】)对应,以0开始

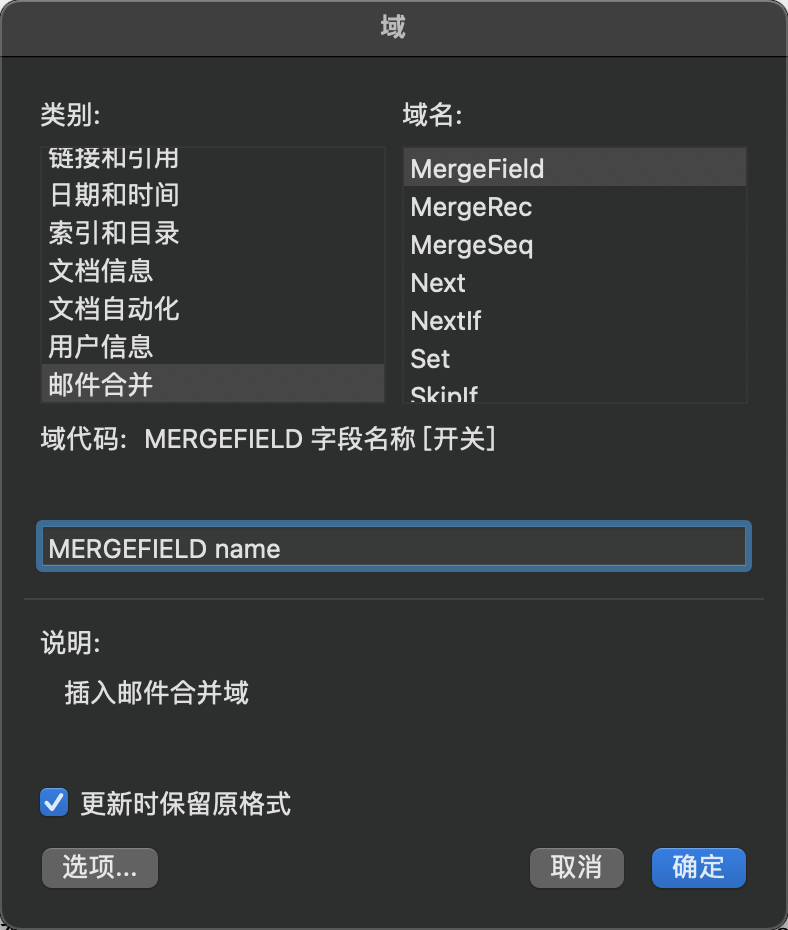
- 模板文件需添加对应的
域 ,邮件合并,MERGEFIELD
- 注意 域的名字要和
name=str(table.row_values(i)[0]) 中的变量名字相同,例如 name

- 批量处理主文件 excel2word.py
- 一键执行文件 excel2word.command
执行
finder 中双击excel2word.command即可
参考
